PDF OCR 识别(pdfClaw)
第一步:进入「PDF OCR」
打开「PDF OCR 识别」页面,适合扫描件、图片型 PDF,输出可搜索、可复制的 PDF。
第二步:上传 PDF
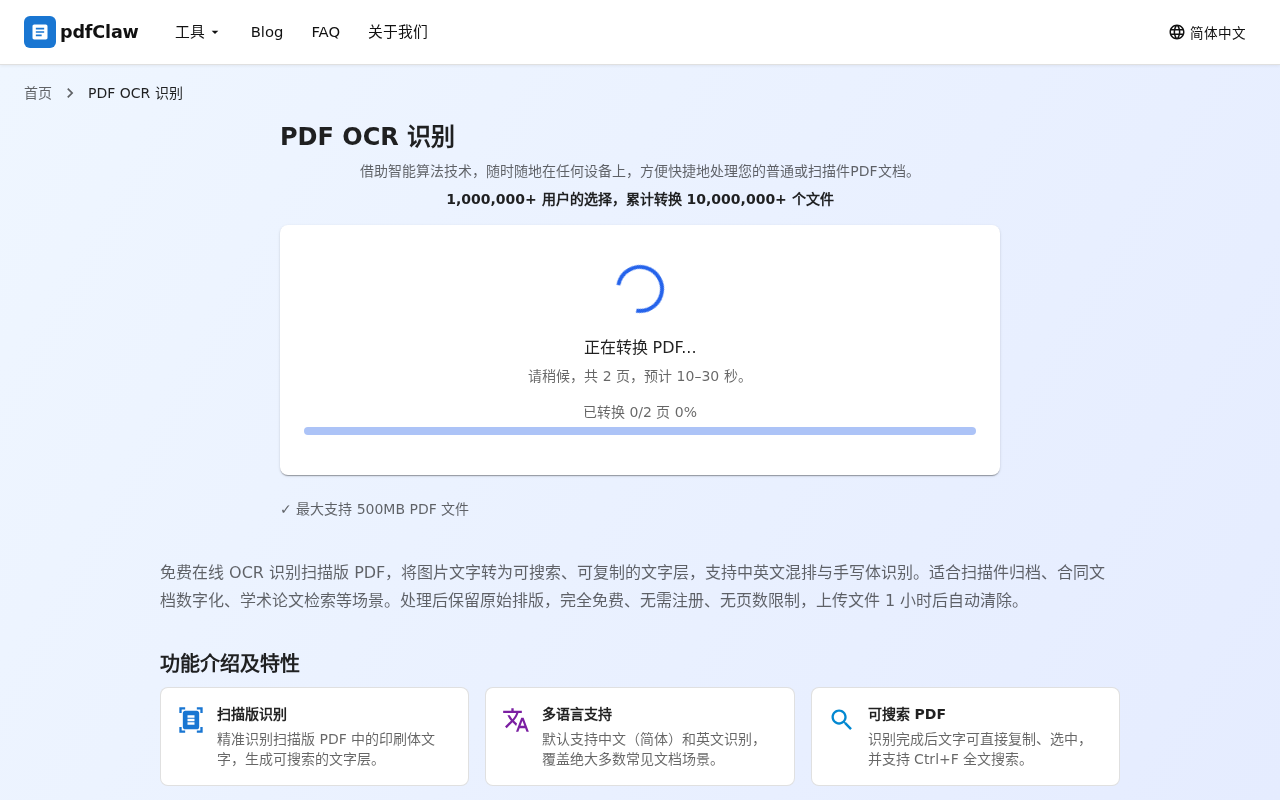
上传扫描版或图片为主的 PDF,上传后自动开始识别与转换。
第三步:等待处理完成
OCR 耗时与页数、清晰度有关,请耐心等待页面提示完成。
第四步:下载可搜索 PDF

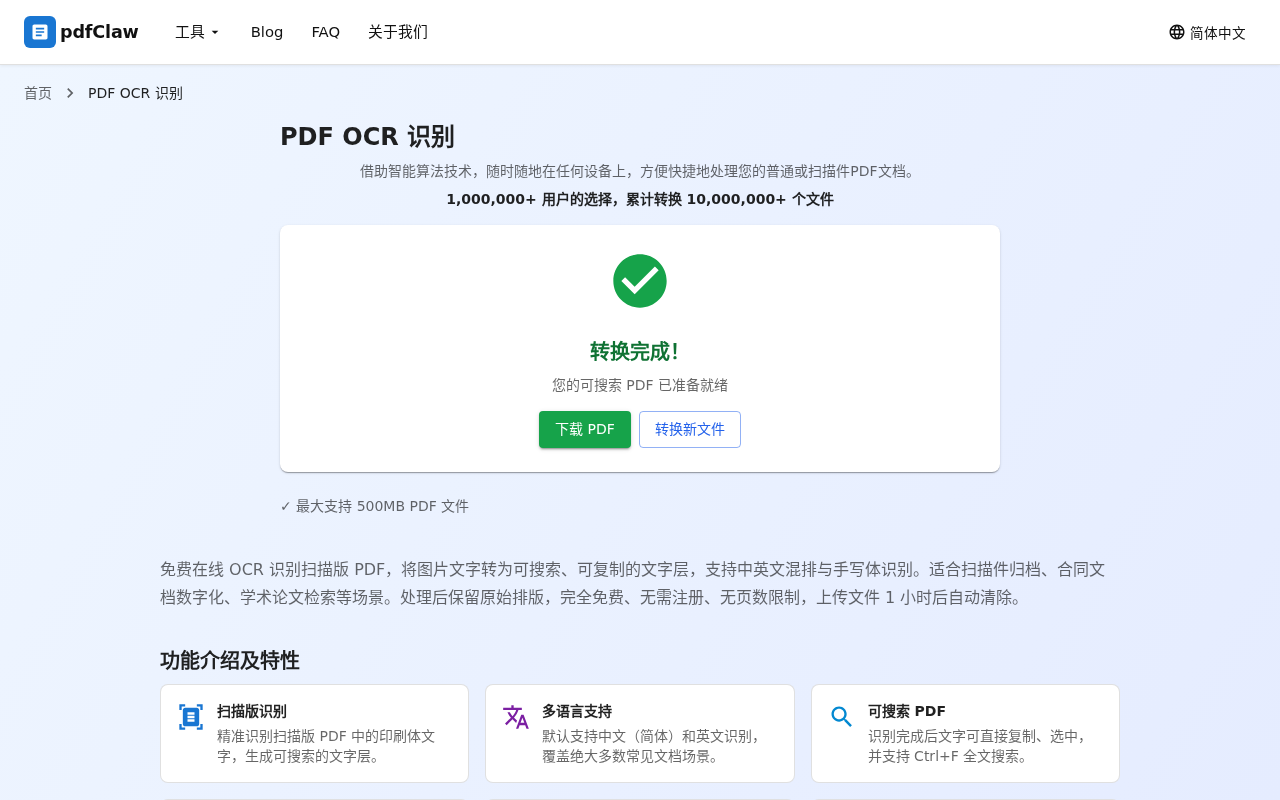
完成后下载新的 PDF,即可在阅读器里搜索、复制文字。
总结
以上是「PDF OCR 识别」从上传到下载的完整使用说明。